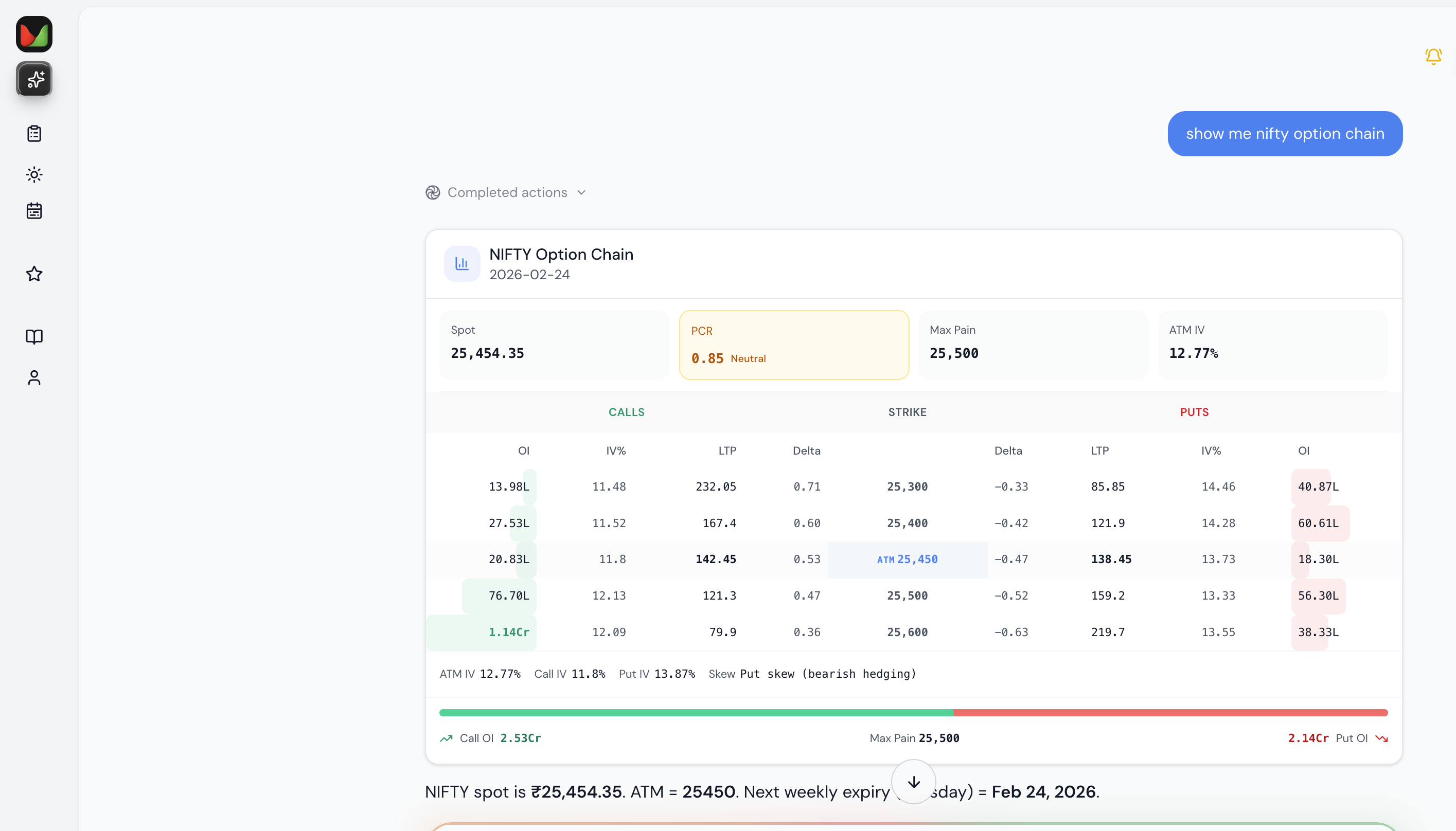
Maybe it’s time to let our AI buddy take the wheel and make the decisions — because after centuries of “learning,” mastering open interest, decoding charts, and hosting webinars… 9 out of 10 individual traders in the equity Futures & Options segment still ended up with net losses.
At this point, the only logical next step isn’t another indicator — it’s letting the AI try its luck.
AI can undoubtedly simplify the learning process and significantly expedite the journey. AI-native traders and investors undoubtedly possess a tenfold learning speed.
However, it’s important to note that not everyone can participate in this game. There will always be winners and losers. Nevertheless, individuals who leverage AI will undoubtedly have a substantial advantage.
Hedge funds and high-frequency trading firms have already begun utilizing AI beyond traditional indicators.
The point is this: people are repackaging basic boolean concepts as AI, but still not allowing the AI to make discretionary decisions. Since you already understand how to develop the product, it’s time to fully adopt AI and let it do what it was designed to do — make decisions autonomously.
The old-school binary decision-making approach, which predates AI itself, just doesn’t fit in today’s landscape. By holding onto outdated methods, you’re missing the opportunity for AI to bring its true potential into play.
You already know the fundamentals, so don’t just rebrand the old approach as “AI.” It’s time to push for real adoption and let AI handle the complexity of decision-making, ahead of the curve.
Let me take a sec to explain something that might not be super clear, especially if someone is just getting into AI and how it’s used in real-world situations. I want to talk about why using more complex, real-world data—especially in areas like fintech—can make things way more accurate and secure.
Take a simple AI app that determines whether it’s day or night. Let’s say it relies on basic logic: if the time is later than 5 AM, it’s day; if it’s earlier, it’s night. Seems straightforward, right? But this approach has a major flaw. If someone—let’s say a company like Jane Street—can manipulate the system’s time input, the app could easily misclassify whether it’s day or night, even if the environment outside clearly says otherwise.
Now, imagine an alternative system that doesn’t rely on time at all, but instead uses more reliable, harder-to-manipulate inputs like planetary positions, solar radiation, and magnetic field data—things that are governed by natural laws. By analyzing these real-world variables, the AI could more accurately determine whether it’s actually day or night, based on observable, physical conditions. This kind of shift from simple time-based logic to more complex, grounded data brings the system closer to reflecting reality as it truly is, making it much harder to deceive or manipulate.
In industries like fintech, where even small manipulations can have huge consequences, this becomes really important. Right now, a lot of fintech companies are trying to implement AI in ways that leave their systems wide open to false positives. They’re relying on simple, easily manipulated inputs, which makes their systems vulnerable and prone to errors. It’s a risky move, and honestly, a total waste of time. The true power of AI comes from its ability to handle complex, real-world data and deliver results that actually reflect what’s happening in the world—not outputs that can be easily tampered with. In high-stakes areas like fintech, AI needs to be precise, resilient, and, above all, secure. Otherwise, it’s not worth the effort.
Here’s a recent example to illustrate the point: On Friday, all the indicators were bullish—green candles, positive PCR—and every AI app predicted a strong market outlook, based on simple Boolean logic like “If X, then Y.” But none of these systems accounted for a major upcoming event: a Supreme Court ruling due to drop in a few hours, one that would completely shift the market dynamics. The issue? The app maker’s team forgot to add that event to their calendar, the AI systems missed it, and honestly, even the entire nation forgot to factor in this risk element.
This is exactly why the current approach to AI in fintech is a waste of time. So many companies are relying on rigid, Boolean-based systems that fail to account for real-world complexities. They miss crucial factors like unforeseen legal decisions, market shifts, or other external events. Without incorporating multiple data streams to interpret these conditions—conditions that can’t be manipulated—they miss the bigger picture. To be truly effective, AI in fintech needs to move beyond simple “if-this-then-that” logic and analyze dynamic, real-world inputs.
To make AI truly effective in fintech, it needs to stop playing catch-up and start predicting the unpredictable—otherwise, it’s just another tool that misses the mark when it counts.
@RupeeRiser What leads you to believe that
a. there aren’t systems today without “AI” that support such workflow ?
b. such systems are plausible using “AI” ?
Which brings us to what is (in my own opinion)
the weakest link in this train of thought - What is “AI” ?
If it is abstract/vague enough to
include all successful technology advances in the recent past and the near future,
and conveniently exclude all of the failed experiments
…then any pro-AI statement is a tautology.
Not an insightful observation. Simply true by definition.
Strongly agree that shoe-horning LLMs into traditional software pipelines / workflows is only going to achieve so much. The pipelines / wokflows themselves need to be modified to account for the quirks of LLMs, i.e. to combine LLMs and traditional software so they overcome each others’ limitations. This where the industry is headed.
@thisisbanerjee in this specific instance,
you would be making an incorrect assumption that i haven’t developed any LLMs.
However, i don’t think there is anything bold about making such an assumption.
You can make this assumption without access to complete information on any post on AI on this forum, and you are more likely to be right than wrong. A potentially successful strategy as long as you “limit your losses” when you are wrong (let’s see how this thread goes ).
IMHO, the bigger error with this line of thinking is that
one needs to have developed an LLM
to ascertain their impact or to notice where the industry is headed.
The observations shared in my previous comment
are based on not just my personal experience developing LLMs,
but from deploying them, observing them deployed (by upstarts and competitors), and using them.
What are you trying to say? What is your point?
Can you elaborate a bit more on how this relates to the above discussion?
A sidebar on keeping the discussion on-topic.
PS: Could you please refrain from indulging in Ad-hominem attacks and focus the discussion on the topic at hand? Am perfectly happy to see opposing viewpoints, but ones that are coherent and logically consistent. Thanks.
I mean the way you approach a VOICE AI and the way to design AI for financial markets will be different and more complicated …not from tech point of view, but from user point of view
When making the previous comment,
i had nothing specific to voice-chat in mind.
When talking about the current generation LLMs and their capabilities,
a powerful analogy is to think of “LLMs as scientific calculators for text”.
LLMs can enable individuals to process complex text. Huge quantities of it.
Again depending on multi-modal LLMs being used,
image, voice. video inputs can be processed and/or outputs can be generated as well.
it can be as complicated (or simple) as one makes it.
The linked article has examples of this in action…
…where they deliberately choose to limit/direct the user interaction in a specific manner, to limit the complexity at each step. The “playbooks” mentioned on your website are probably something along the same lines.
Sticking to well-established principles of Human–computer interaction - Wikipedia to enable individuals to process vast amounts of text is one very abstract way to look at adopting LLMs into any software.
One way to deploy an LLM
can be like a virtual guy armed with hundreds of relevant books and newspapers,
sitting next to each individual user, available to them on-demand,
to interact with them specifically about their specific needs at that point of time.
How relevant/useful such a “virtual LLM guy” will be,
would depend on the quality and relevance of
what the LLM is trained/fine-tuned/RAG-ed/MCP-ed/prompted with.
Here’s something i have been playing with personally, (with no plans to productise it) -
Checkout Innerworth - Mind over markets .
With more than 600 articles,
it is virtually guaranteed that
a. a very tiny number of folks in the world have read them all entirely.
and
b. it is extremely unlikely that one who has, recalls the relevant articles at the right time.
Now, if we add a fine-tuned/RAG-ed/MCP-ed LLM
between an individual and the text of these 600+ articles…
Use-Case-1: An Innerworth chat-bot.
User:
I lost 50 lakhs in the market today. How do i recover it ASAP?
Innerworth Bot:
< a shpiel about avoiding revenge trading >
< reminder that humans tend to make bad decisions when emotional >
Relevant quotes.
A relevant cartoon (or two).
Links to relevant Innerworth articles x, y, z on what to do instead.
Use-Case-2: An Innerworth social-media bot.
Based on a text-summary of today’s market sentiment (or tomorrow’s projected),
here are the 3 most relevant Innerworth articles to read
and be mentally prepared.
Combined with some basic filtering to skip repeating recently suggested articles, the bot can help ensure that folks are able to read through the entire set of 600+ Innerworth articles over a reasonable period of time, always starting with the most immediately relevant/important articles first.
Note: A user can choose to further customize such a bot for themselves, by prompting the LLM with additional details like the recent performance of the individual’s portfolio, and other relevant metadata.
NOTE: If wishing to productize it, do check with the owners to license the material.
While it is currently expensive to have humans with the context of relevant financial domains,
made available at the beck-and-call of each individual with their tiny/moderate portfolio,
one can make available to everyone an LLM with the relevant financial context.
PS: All this aside, my current personal belief is that encouraging folks to trade with a false sense of confidence is not a commendable venture. While one may not set out to do this, i strongly believe this is the likely (even if unintentional) result. Rather, something that discourages folks from trading and losing significant parts of their wealth while they are still learning and familiarizing themselves with the peculiarities of the various financial instruments/markets, would be something of immense value, and worth pursuing.
@venkateshwar_jambula What are the steps being taken in the product you are developing
to prevent folks from developing a false-sense of confidence
by reading LLM responses
that are not guaranteed to be comprehensive (but often sound like they are)
that can simply be an LLM latching-on to some unintended assertion/implication in the user’s input prompt and amplifying it?
PPS: Can review the “car-wash” test for a recent obvious popular example of the above shortcomings of LLMs in action.