Hi Traders,
If anyone is familiar with how classifications are done in Index Futures for all participants under the FII/DII summary, I’d appreciate your insights.
Kindly share your thoughts by emailing me at [email protected] .
Thank you in advance for your help!
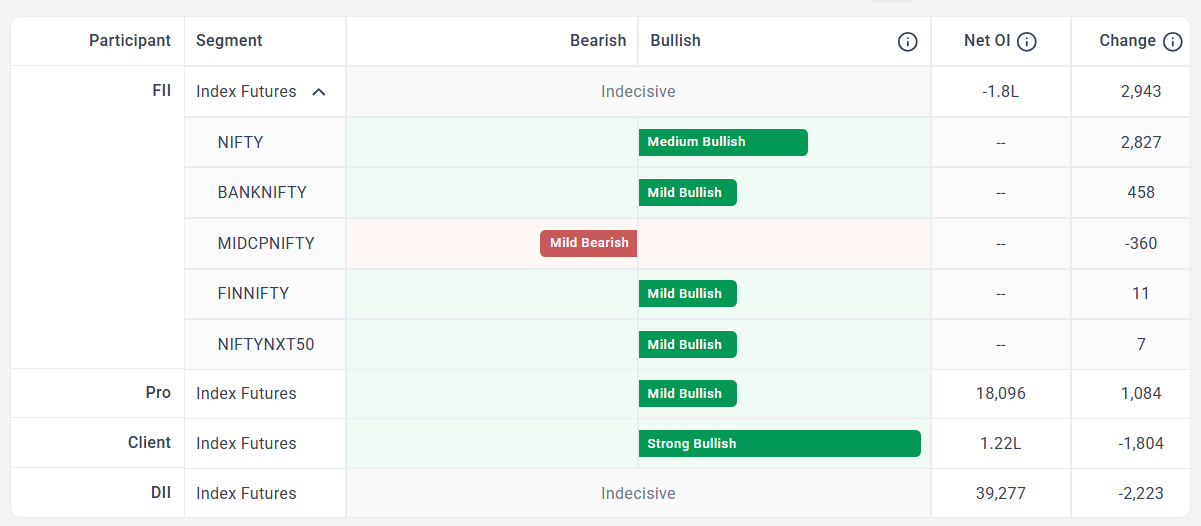

yes i am asking these only,net oi data is taken from nse ,participant wise open interest data,then change in oi is calculated from current day net oi -previous day net oi;;then from these net oi and oi change data,sensibull predicts market sentiment like mild,medium,strong bearish/indecisive/mild,medium,strong bullish;I am asking the classifications methodology involved?I need to know the strategy behind this:If anyone knows means , I’d appreciate your insights.
Kindly share your thoughts by emailing me at [email protected] .or reply here in the comments section
Thank you in advance for your help!
…aaand we have come full-circle on this duplicate topic-thread. ![]()
Sensibull’s recent clarifications on this
(to the extent that they are happy to disclose)
are in this recent thread -
I’ve been following that thread closely and have been trying to reverse-engineer a strategy that matches the Sensibull platform’s classifications — but so far, my results don’t align exactly with theirs.
If anyone here has figured out an approach that comes close, I’d be grateful for your insights.
You can reach me at [email protected].or reply here ![]()
Thanks in Advance
Why? ![]()
It is not as if Sensibull’s classification is some industry standard
nor is it based on some accepted methodology.
( They said as much in their responses on the original thread linked above. )
Alternately, another way to go about this would be
for you to share your methodology, implementation, and results (highlighting the deviations).
- Interested folks can then review the methodology and suggest tweaks,
- or review the implementation or attempt to reproduce the results using the implementation,
- and identify/share any issues with the implementation (if any).
Again, all of this would be something interesting purely from an academic perspective, unless Sensibull’s model drives significant volume (in the form of its users blindly following the model) in the market - in which case, having a model that can predict what Sensibull’s model will suggest tomorrow, can be an edge. ![]()
(PS: in addition to not documenting the exact methodology, i would presume hope that Sensibull is adding some noise to their model, or tweaks it gradually (over some unspecified duration), to avoid falling prey to such adverserial strategies against it.)